

Traditionally migrating data changes between applications with was implemented real-time or near real-time using APIs developed on source or target with a push or pull mechanism, incremental data transfers using database logs, batch processes with custom scripts etc., These solutions had drawbacks like
- Source and target system code changes catering to specific requirement
- Near real-time leading to data loss
- Performance issues when the data change frequency and/or the volume is high
- Push or pull mechanism leading to high availability requirement
- adding multiple target applications would need a larger turnaround time
- Database specific real-time migration was confined to vendor specific implementation
- Scalability of the solution was time and cost intensive operation
Change data capture (CDC) refers to the process of identifying and capturing changes made to data in a database and then delivering those changes in real-time to a downstream process or system. Moving data from one application database into another database with a minimal impact on the performance of the applications is the main motto behind this design pattern. It is a perfect solution for modern cloud architectures since it is a highly efficient way to move data across a wide area network. And, since it’s moving data in real-time, it also supports real-time analytics and data science.
In most of the scenarios CDC is used to capture changes to data and take an action based on that change. The change to data is usually one of insert, update or delete. The corresponding action usually is supposed to occur in the target system in response to the change that was made in the source system. Some use cases include:
- Moving data changes from OLTP to OLAP in real time
- Consolidating audit logs
- Tracking data changes of specific objects to be fed into target SQL or NoSQL databases
Overview:
In the following example we would be using CDC between source and target PostgreSQL instances using Debezium connector on Apache Kafka with a Confluent schema registry to migrate the schema changes onto the target database. We would be using docker containers to setup the environment.
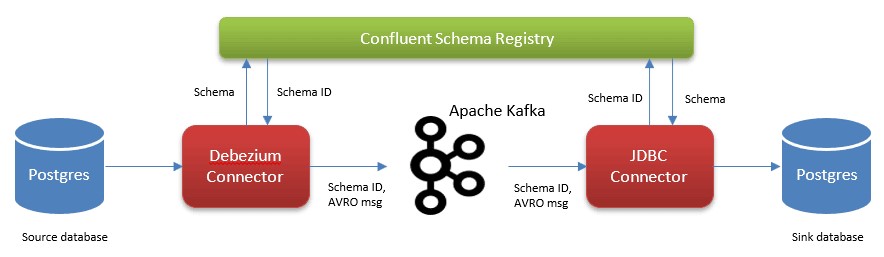
Now, let us setup the docker containers to perform CDC operations. In this article we would be focusing only on insert and update operations.
Docker Containers:
- In a Windows or Linux machine, install Docker and create a docker-compose.yml file with the following configuration.





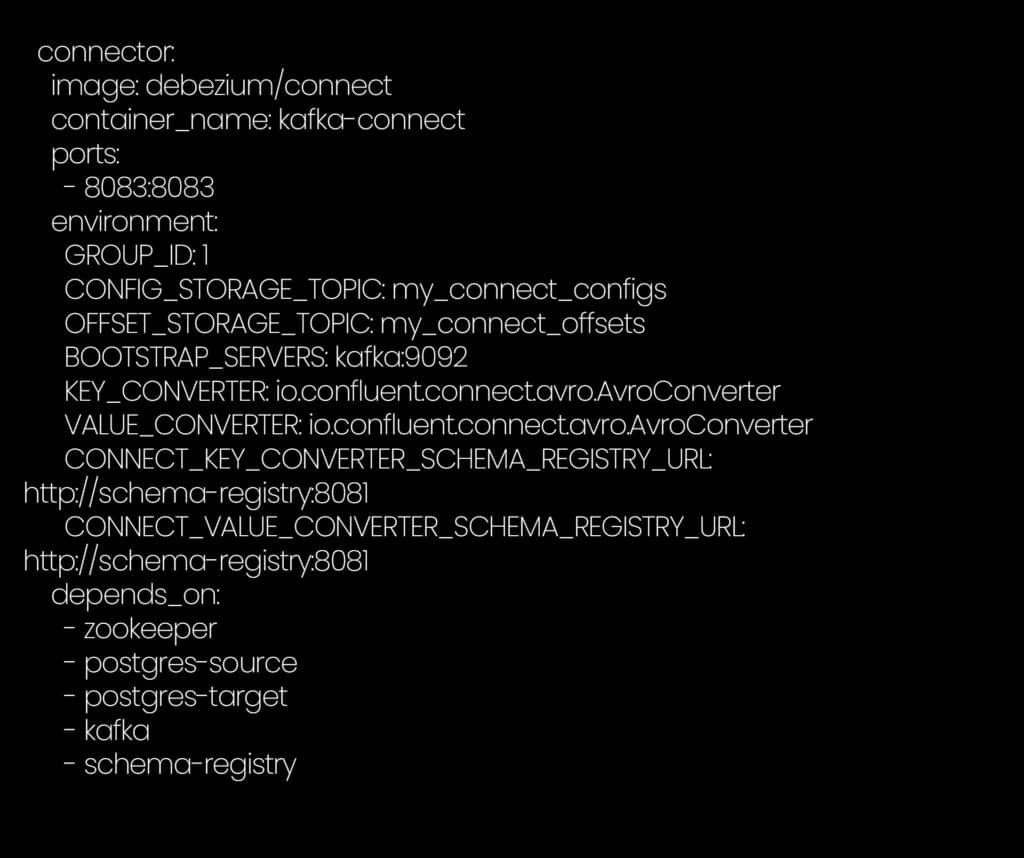
- Run the docker-compose.yml file by navigating to the directory in which the file was created using command prompt or a terminal and run the below command.

Debezium plugin configuration:
- Once the docker containers are created, we need to copy Debezium kafka connect jar files into the plugins folder using the below command.

- Restart the kafka-connect container after the copy command is executed.

Database configuration:
- Connect to the postgres-source and postgres-target databases using psql or pgAdmin tool.
- Create a database named testdb in both the servers.
- Create a sample table in both the databases.
Ex: create table test(uuid serial primary key, name text);
- In postgres-source database execute the below command to change WAL_LEVEL to logical.
Alter system set wal_level=’logical’;
- Restart the postgres-source docker container using the docker stop and start commands.
Source Connector:
Using any of the REST client tools, like Postman, send a POST request to the following endpoint with the below mentioned body to create the source connector.
Endpoint: http://localhost:8083/connectors